Much of the legacy biodiversity literature provides a vast wealth of extremely valuable content for taxonomic research. However, This scientific literature is almost entirely in paper-print format and thus is not directly accessible through the Internet. Recent efforts on transforming printed text into electronic text resources using document scanning and OCR (Optical Character Recognition) techniques has increase overall access to publication dramatically.
Due to imperfections in current OCR technology, sources such as photocopies of old printed pages, particularly ancient taxonomic monographs that are over 100 years old, can still cause many OCR errors due to outdated fronts, complex terms, and aspects such as blemishes and stains on the scanned pages. To reduce the impact of OCR errors on the identification of taxonomic names, a mechanism for error checking and correction is required.
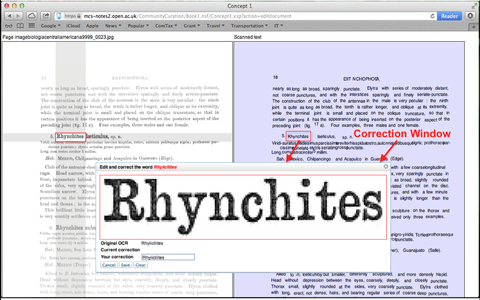
We here developed a web service demo that allows users to intervene in the process of OCR-error correction. Given a taxonomic monograph with multiple pages, the tool allows the user to decide the page number, the display mode of the selected page, and the navigation type of the user interface. Figure 1 displays a user interface with respect of a selected page. The left-hand panel is the photocopy image of the original page, and the right-hand panel is the corresponding OCR-scanned text, which is directly extracted from the associated DjVu XML file created by the OCR software.
When a word is selected using the navigation content in the right-hand panel, a small error-correction window (see Figure 2) is pop up, and the user is allowed to make possible modification according to the enlarged image of the target word appearing on the pop-up window. Once the user clicks the “Save” button, the correction information about the target word will be stored in the back-end database, and then the corrected word will replace the old one and appear in the right-hand OCR text.